[7] Dodawanie/usuwanie OSD
20 lipca 2020Sieć wyglądać/wyglądała następująco. Węzeł [node4] zostanie najpierw dodany, a następnie usunięty.
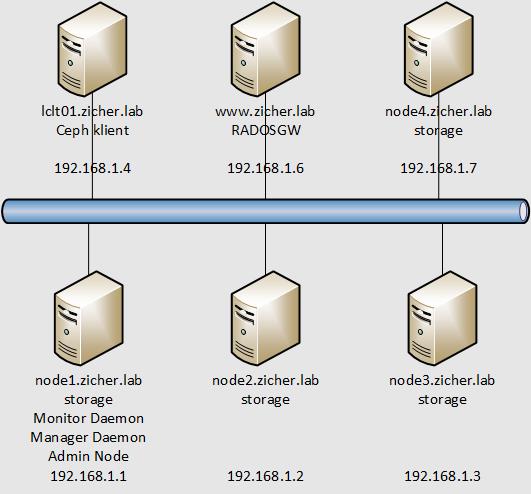
[1] Dodamy teraz węzeł [node4] to OSD z [Admin Node]. Jako urządzenie blokowe użyjemy [/dev/sdb].
# transferujemy klucz publiczny [root@node1 ~]# ssh-copy-id node4 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'node4 (192.168.1.7)' can't be established. ECDSA key fingerprint is SHA256:XziJ4W8VLjGjmPTnreQGjKZWTinoFLisikci9DeEQJ8. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@node4's password: # wpisz hasło root'a@node4 Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'node4'" and check to make sure that only the key(s) you wanted were added. # jeżeli Firewalld pracuje zezwól na ruch następującym usługom [root@node1 ~]# ssh node4 "firewall-cmd --add-service=ceph --permanent; firewall-cmd --reload" success success # zainstaluj potrzebne pakiety [root@node1 ~]# ssh node4 "dnf -y install centos-release-ceph-octopus epel-release; dnf -y install ceph" #przekopiuj potrzebne pliki [root@node1 ~]# scp /etc/ceph/ceph.conf node4:/etc/ceph/ceph.conf ceph.conf 100% 385 17.4KB/s 00:00 [root@node1 ~]# scp /etc/ceph/ceph.client.admin.keyring node4:/etc/ceph ceph.client.admin.keyring 100% 151 195.6KB/s 00:00 [root@node1 ~]# scp /var/lib/ceph/bootstrap-osd/ceph.keyring node4:/var/lib/ceph/bootstrap-osd ceph.keyring 100% 129 7.4KB/s 00:00 # skonfigurujmy teraz OSD [root@node1 ~]# ssh node4 "chown ceph. /etc/ceph/ceph.* /var/lib/ceph/bootstrap-osd/*; parted --script /dev/sdb 'mklabel gpt'; parted --script /dev/sdb "mkpart primary 0% 100%"; ceph-volume lvm create --data /dev/sdb1" Running command: /usr/bin/ceph-authtool --gen-print-key Running command: /usr/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new 5e105c55-3e64-452e-a6f2-8b6f8f27179a Running command: /usr/sbin/vgcreate --force --yes ceph-670d9bd8-f41c-437f-a389-762fdc8922e4 /dev/sdb1 stdout: Physical volume "/dev/sdb1" successfully created. stdout: Volume group "ceph-670d9bd8-f41c-437f-a389-762fdc8922e4" successfully created Running command: /usr/sbin/lvcreate --yes -l 100%FREE -n osd-block-5e105c55-3e64-452e-a6f2-8b6f8f27179a ceph-670d9bd8-f41c-437f-a389-762fdc8922e4 stdout: Logical volume "osd-block-5e105c55-3e64-452e-a6f2-8b6f8f27179a" created. Running command: /usr/bin/ceph-authtool --gen-print-key Running command: /usr/bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-3 Running command: /usr/sbin/restorecon /var/lib/ceph/osd/ceph-3 Running command: /usr/bin/chown -h ceph:ceph /dev/ceph-670d9bd8-f41c-437f-a389-762fdc8922e4/osd-block-5e105c55-3e64-452e-a6f2-8b6f8f27179a Running command: /usr/bin/chown -R ceph:ceph /dev/dm-3 Running command: /usr/bin/ln -s /dev/ceph-670d9bd8-f41c-437f-a389-762fdc8922e4/osd-block-5e105c55-3e64-452e-a6f2-8b6f8f27179a /var/lib/ceph/osd/ceph-3/block Running command: /usr/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring mon getmap -o /var/lib/ceph/osd/ceph-3/activate.monmap stderr: got monmap epoch 2 Running command: /usr/bin/ceph-authtool /var/lib/ceph/osd/ceph-3/keyring --create-keyring --name osd.3 --add-key AQCkthVf5MibMBAAbdHufA5WjMyyYUZwvn8NXg== stdout: creating /var/lib/ceph/osd/ceph-3/keyring added entity osd.3 auth(key=AQCkthVf5MibMBAAbdHufA5WjMyyYUZwvn8NXg==) Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3/keyring Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3/ Running command: /usr/bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 3 --monmap /var/lib/ceph/osd/ceph-3/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-3/ --osd-uuid 5e105c55-3e64-452e-a6f2-8b6f8f27179a --setuser ceph --setgroup ceph --> ceph-volume lvm prepare successful for: /dev/sdb1 Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3 Running command: /usr/bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-670d9bd8-f41c-437f-a389-762fdc8922e4/osd-block-5e105c55-3e64-452e-a6f2-8b6f8f27179a --path /var/lib/ceph/osd/ceph-3 --no-mon-config Running command: /usr/bin/ln -snf /dev/ceph-670d9bd8-f41c-437f-a389-762fdc8922e4/osd-block-5e105c55-3e64-452e-a6f2-8b6f8f27179a /var/lib/ceph/osd/ceph-3/block Running command: /usr/bin/chown -h ceph:ceph /var/lib/ceph/osd/ceph-3/block Running command: /usr/bin/chown -R ceph:ceph /dev/dm-3 Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3 Running command: /usr/bin/systemctl enable ceph-volume@lvm-3-5e105c55-3e64-452e-a6f2-8b6f8f27179a stderr: Created symlink /etc/systemd/system/multi-user.target.wants/ceph-volume@lvm-3-5e105c55-3e64-452e-a6f2-8b6f8f27179a.service → /usr/lib/systemd/system/ceph-volume@.service. Running command: /usr/bin/systemctl enable --runtime ceph-osd@3 stderr: Created symlink /run/systemd/system/ceph-osd.target.wants/ceph-osd@3.service → /usr/lib/systemd/system/ceph-osd@.service. Running command: /usr/bin/systemctl start ceph-osd@3 --> ceph-volume lvm activate successful for osd ID: 3 --> ceph-volume lvm create successful for: /dev/sdb1 # klaster musi zostać przebudowany, w zależności od prędkości cieci, dysków może to potrwać od kilku minut do kilku godzin [root@node1 ~]# ceph -s cluster: id: 8a31deb0-114c-4639-8050-981f47e5403c health: HEALTH_OK services: mon: 1 daemons, quorum node1 (age 2d) mgr: node1(active, since 10m) mds: cephfs:1 {0=node1=up:active} osd: 4 osds: 4 up (since 18m), 4 in (since 18m) rgw: 1 daemon active (www) task status: scrub status: mds.node1: idle data: pools: 9 pools, 225 pgs objects: 269 objects, 15 MiB usage: 4.3 GiB used, 196 GiB / 200 GiB avail pgs: 225 active+clean
[2] Aby usunąć węzeł OSD z istniejącego klastra wykonaj poniższe polecenia. Usuwamy wcześniej dodany klaster [node4].
# sprawdzamy klaster [root@node1 ~]# ceph -s cluster: id: 8a31deb0-114c-4639-8050-981f47e5403c health: HEALTH_OK services: mon: 1 daemons, quorum node1 (age 2d) mgr: node1(active, since 13m) mds: cephfs:1 {0=node1=up:active} osd: 4 osds: 4 up (since 21m), 4 in (since 21m) rgw: 1 daemon active (www) task status: scrub status: mds.node1: idle data: pools: 9 pools, 225 pgs objects: 269 objects, 15 MiB usage: 4.3 GiB used, 196 GiB / 200 GiB avail pgs: 225 active+clean # sprawdzamy drzewo i wybieramy węzeł do usunięcia [root@node1 ~]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.19519 root default -3 0.04880 host node1 0 hdd 0.04880 osd.0 up 1.00000 1.00000 -5 0.04880 host node2 1 hdd 0.04880 osd.1 up 1.00000 1.00000 -7 0.04880 host node3 2 hdd 0.04880 osd.2 up 1.00000 1.00000 -9 0.04880 host node4 3 hdd 0.04880 osd.3 up 1.00000 1.00000 # wybieramy [node4] czyli wpisujemy OSD ID który chcemy usunąć [root@node1 ~]# ceph osd out 3 marked out osd.3. # możemy na żywo obserwować status przebalansowania klastra wydając poniższe polecenie, aby wyjść z podglądy naciśnij [CTRL+c] [root@node1 ~]# ceph -w cluster: id: 8a31deb0-114c-4639-8050-981f47e5403c health: HEALTH_WARN Reduced data availability: 37 pgs inactive, 105 pgs peering Degraded data redundancy: 4/807 objects degraded (0.496%), 4 pgs degraded services: mon: 1 daemons, quorum node1 (age 2d) mgr: node1(active, since 16m) mds: cephfs:1 {0=node1=up:active} osd: 4 osds: 4 up (since 24m), 3 in (since 19s); 39 remapped pgs rgw: 1 daemon active (www) task status: scrub status: mds.node1: idle data: pools: 9 pools, 225 pgs objects: 269 objects, 15 MiB usage: 4.3 GiB used, 196 GiB / 200 GiB avail pgs: 71.111% pgs not active 4/807 objects degraded (0.496%) 83 peering 65 active+clean 50 activating 23 remapped+peering 4 activating+degraded progress: Rebalancing after osd.3 marked out (13s) [............................] 2020-07-20T17:46:44.467532+0200 mon.node1 [WRN] Health check update: Reduced data availability: 37 pgs inactive, 105 pgs peering (PG_AVAILABILITY) 2020-07-20T17:46:45.578323+0200 mon.node1 [WRN] Health check update: Degraded data redundancy: 4/807 objects degraded (0.496%), 4 pgs degraded (PG_DEGRADED) 2020-07-20T17:46:49.728306+0200 mon.node1 [WRN] Health check update: Reduced data availability: 39 pgs inactive, 105 pgs peering (PG_AVAILABILITY) 2020-07-20T17:46:50.581436+0200 mon.node1 [WRN] Health check update: Degraded data redundancy: 5/807 objects degraded (0.620%), 5 pgs degraded (PG_DEGRADED) ... ... # otrzymując ten komunikat wiemy, że wszystko poszło OK 2020-07-20T17:49:29.844714+0200 mon.node1 [INF] Cluster is now healthy # po przejściu statusu na [HELATH_OK], możemy wyłączyć usługę OSD na docelowym, usuwanym węźle [root@node1 ~]# ssh node4 "systemctl disable --now ceph-osd@3.service" Removed /run/systemd/system/ceph-osd.target.wants/ceph-osd@3.service. # usuwamy węzeł, którego OSD ID wyspecyfikowaliśmy wcześniej [root@node1 ~]# ceph osd purge 3 --yes-i-really-mean-it purged osd.3 # sprawdzamy status klastra [root@node1 ~]# ceph -s cluster: id: 8a31deb0-114c-4639-8050-981f47e5403c health: HEALTH_OK services: mon: 1 daemons, quorum node1 (age 2d) mgr: node1(active, since 36s) mds: cephfs:1 {0=node1=up:active} osd: 3 osds: 3 up (since 2m), 3 in (since 7m) rgw: 1 daemon active (www) task status: scrub status: mds.node1: idle data: pools: 9 pools, 225 pgs objects: 269 objects, 15 MiB usage: 3.3 GiB used, 147 GiB / 150 GiB avail pgs: 225 active+clean